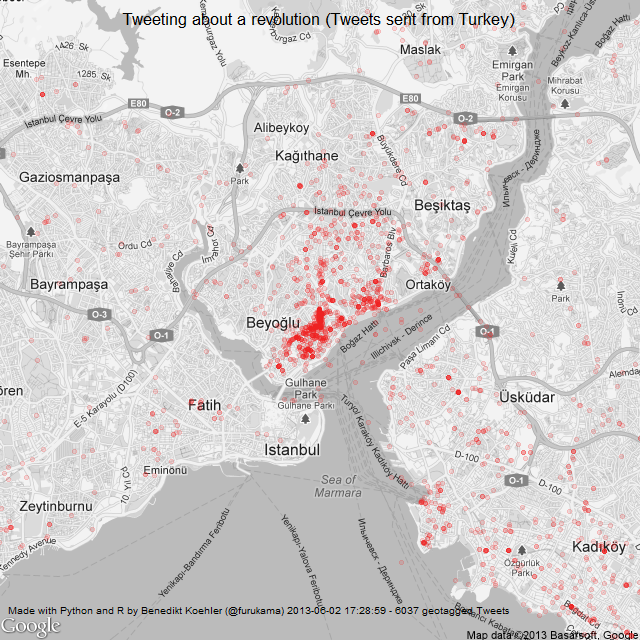
Data is the new media. Darüber habe ich auch schon geschrieben. Medien, nach dem althergebrachten Begriff, verschränken sich immer mehr mit Daten, unmittelbar mit Data Storytelling, Datenjournalismus und dergleichen mehr, mittelbar dadurch, dass Search, Werbe-Targeting, Filterung von Inhalten und andere Technologien auf Basis von Vorhersagemodellen, immer stärker beeinflussen, was wir als Medien-Inhalte präsentiert vorfinden.
Daher bin ich überzeugt, dass es sinnvoll ist, mit Slow Media anzufangen und zu dann fragen, wie es um Slow Data bestellt ist.
Sorgfältig gepflegte, kleine Datensätze
Das, was über alle Maßen nützlich ist, ist das richtige Verfahren.
Godfrey Harold Hardy
Datenbanken aus dem Direktmarketing tendieren dazu, nicht unbedingt Top Qualität zu bieten (sorry liebe CRM-Leute, aber ich weiß wovon ich da rede). Viele Datensätze sind nur teilweise qualifiziert, wenn überhaupt. Und dazu sind die Informationen, auf die das Targeting fußen soll häufig veraltet.
Kleine Stichproben können große Datenhaufen verbessern
Ab 2006 war ich für eine der großen Marktforschungsstudien verantwortlich, die Typologie der Wünsche. Diese überaus teure Forschung wurde mit allergrößter Sorgfalt durchgeführt, ganz nach den Regeln der Sozialforschungskunst. Die Fragebögen durchliefen das strengste Lektorat, bevor auch nur in Erwägung gezogen wurde, sie an die Interviewer zu schicken. Die Umfrage wurde als persönliches Interview durchgeführt, die Stichprobe der jährlich 10.000 Befragten mit großer Genauigkeit aus der Bevölkerung gezogen. Eine ständige Qualitätskontrolle wurde über die Ergebnisse gelegt. Und um ganz sicher über die Qualität der Umfrage sein zu können, wurde die Befragung von drei unabhängigen Instituten durchgeführt. So konnten wir stets die Ergebnisse über Kreuz validieren.
Da mein damaliger Arbeitgeber auch im Direktmarketinggeschäft tätig war, mit großen Adressdatenbanken, mehreren Call-Centern und Logistik, hatten wir ein Verfahren entwickelt, die sorgfältig kuratierten Daten unserer Marktforschung mit ihrer (für Direktmarketing-Verhältnisse) kleinen Fallzahl, zur Kalibrierung der typisch “schmutzigen” Datensätze des CRM-Geschäfts einzusetzen. Dieser Ansatz hatte so gut funktioniert, dass wir eine Kooperation mit der Deutschen Post darauf aufsetzen konnten, diesmal in erheblich größerem Umfang. Unsere kleine, aber wertvollen Daten wurden auf alle 40 Millionen Adressen in Deutschland projiziert.
Als ich für die MediaCom arbeitete, war ich an einem ähnlichen Projekt beteiligt. Die Fernsehquoten werden in den meisten Märkten in teuren Zuschauerpanels gemessen, die üblicher Weise von Branchenverbänden bezahlt werden, wie etwa durch BARB in Großbritannien oder durch die AGF in Deutschland. Diese Panels bleiben verständlicher Weise auf wenige Tausend Haushalte beschränkt. Da es aber nur wenig mehr als zehn relevante TV-Kanäle gibt, ist diese Anzahl ausreichend für die Mediaplanung. Im Internet dagegen ist die Mediennutzung viel stärker fragmentiert, so dass ein Panel dieser Art kaum sinnvoll einzusetzen ist. Wir verwendeten daher die Daten, die wir über unser Web-Tracking gesammelt hatten, wieder etwa 40 Millionen Datensätze. Und wieder fanden wir einen Weg, die Daten aus dem Zuschauerpanel der Fernsehforschung in die Online-Daten einfließen zu lassen, so dass wir berechnen konnten, wie wahrscheinlich der Nutzer hinter einem bestimmten Cookie eine Werbekampagne bereits im Fernsehen gesehen haben könnte oder nicht. Wiederum wurde der Wert einer Big Data Datenbank durch kleine, aber sorgfältig kuratierte und hochspezialisierte Daten wesentlich gesteigert.
Wissenschaftliche Erkenntnisse in Big Data einbringen
Des Archimedes wird man sich noch erinnern, wenn Aeschylus längst vergessen ist, da die Sprachen sterben, nicht aber Mathematische Ideen.
Godfrey Harold Hardy
Weitere Beispiele, wie kleine, aber sorgfältig kuratierte Daten eine zentrale Rolle in der Data Science spielen, finden sich bei Daten, die wissenschaftliche Erkenntnisse liefern, die nicht schon an sich in unseren ursprünglichen Daten enthalten sind. Text-Mining funktioniert dann am besten, wenn man quantitative Verfahren einsetzen kann, ohne auf schwierige, kulturelle Konzepte wie “Bedeutung” oder “Semantik” Rücksicht nehmen zu müssen. Relevante Inhalte aus ngram-Rangreihen erkennen oder Textvergleiche mit Cosinus-Vektor-Abstand gehören zu den mächtigsten Werkzeugen, um Texte zu analysieren, selbst wenn diese in unbekannten Sprachen oder Alphabeten verfasst sind. Allerdings erfordern die quantitativen Text-Mining-Verfahren stets eine Vorverarbeitung des Textes: Alle Wörter, die nur einer grammatikalischen Funktion dienen, aber nicht direkt zum Inhalt beitragen müssen zunächst aus dem Text gestrichen werden. Es ist außerdem nützlich, die Wörter in ihre Stammformen zu setzen (was man sich als Infinitiv bei Verben oder Nominativ Singular bei Substantiven vorstellen kann). Diese unverzichtbare Arbeit wird mittels spezieller Corpora geleistet, Wörterbüchern, oder besser gesagt, Bibliotheken, die sämtliche notwendige Information dazu enthalten. Diese Corpora sind von Linguisten handgefertigt. Programmpakete wie das NLTK für Python haben diese Wörterbücher und Regeln auf handliche Weise eingebaut.
In seinem Vortrag “The Sidekick Pattern: Using Small Data to Increase the Value of Big Data” gibt Abe Gong, damals Data Scientist bei Jawbone, weitere Beispiele für Small Data, dass die bleiernen Big Data Haufen in Gold verwandelt. Seine alchimistische Data Science Präsentation sei wärmstens empfohlen.
Daten als Kunst
Mich interessiert Mathematik nur als kreative Kunst.
Godfrey Harold Hardy
“Beautiful Evidence“, wunderschöne Anschauung, so nennt Edward Tufte gute Visualisierung. Information kann uns wahrhaft in wunderschöner Form dargebracht werden. Datenvisualisierung als Kunstform hatte es spätestens in das das Allerheiligste der Hoch-Kunst geschafft, als die Gruppe Asymptote im Jahr 2002 auf der Documenta 11 präsentiert wurde. Waren früher Zeichnungen, Kupfer- oder Stahlstiche wie dieser hier die Illustration zum Text, so sind Infografiken heute die Story selbst.
Generative art ist eine andere, datengetriebene Kunstform. Als ich gerade mit dem Studium begonnen hatte, war endlich Die fraktale Geometrie der Natur soweit abgesunken, dass sie auch in den Mathematikvorlesungen angelangt war. Mit meinem Atari Mega ST verschlang ich jede Zeile Code, die ich in die Finger bekommen konnte. Was mich vor allem beschäftigte waren weniger die (in der Regel ziemlich kitschigen) bunten Fraktalbilder. Ich wollte fraktale Musik machen, Generative Music, die aus meinem Code algorithmisch erstehen würde.
Fraktale als ein Kunst-Ding waren letztlich doch eher modischer Schnickschnack, nicht wirklich geeignet, als Rohstoff für echte Kunst. Im Gegensatz dazu ist die Generative Art insgesamt aber inzwischen zu einer festen Institution in den Künsten erwachsen. Ein Großteil der Musik von heute fußt weitgehend auf algorithmischen Mustern in vielen musikalischen Dimensionen – vom Rhythmus bis zur Melodie, bis zu den Obertonspektren. In der Videokunst ist es ähnlich; auch hier finden sich überall algorithmisch erzeugte Bilder.
Kunst aus Daten wird sich weiter entfalten. Ich bin überzeugt, dass Data Fiction zu einem eigenen Genre wachsen wird.
Data als Kritik
… es gibt keine tiefere oder besser gerechtfertigte Verachtung, als die Menschen die etwas erschaffen gegen die Menschen hegen, die etwas erklären. Darstellung, Kritik und Lob sind Tätigkeiten für Geister zweiter Klasse.
Godfrey Harold Hardy
Kritik bedeutet in Alternativen zu denken. Kritik bedeutet dem zu mistrauen, was uns als Wahrheit verkauft wird. Daten sind stets vieldeutig. Bedeutung wird in die Daten erst durch Interpretation gelegt. Kritik bedeutet, diese Interpretation zu dekonstruieren, um Platz für alternative Sichtweisen zu schaffen. Jene anderen Geschichten, die uns die Daten auch noch erzählen könnten, müssen nicht plausibel sein. Gerade das Absurde enthüllt uns oft die verdeckten Aspekte unserer Modelle. So lange unsere alternativen Interpretationen wenigstens theoretisch möglich sind, sollten wir auch diesen Pfaden folgen und sehen, wohin sie uns führen. Data Fiction bedeutet, Daten zum Werkzeug für Kritik zu machen.
Data Science hat unsere Vorstellung davon verändert, was wir als langlebige Ergebnisse betrachten. In Data Science ziehen wir in der Regel keine Schlüsse, die wir als wahr oder dauerhaft betrachten würden. Vielmehr hoffen wir, dass eine Korrelation oder ein Muster, das wir beobachtet haben wenigstens eine Zeit lang stabil bleiben. Es gibt auch keine Hypothesen mehr, die wir akzeptieren würden, die wir abhaken, nur weil unsere Teststatistik ein signifikantes Ergebnis liefert. Wir würden stets fortfahren, mit den a/b-Tests, um nach alternativen Modellen zu suchen, die den Gewinner der letzten Runde unseres Test-Spiels ersetzen können. In Data Science maximieren wir kritisches Denken, indem wir nicht einmal annehmen, etwas falsifizieren zu können, da wir schon von vornherein nicht davon ausgegangen sind, der bisherige Stand unseres Wissens sei wahr. Wahrheit im Sinne der Data Science bedeutet lediglich die wahrscheinlichste Interpretation zu einer bestimmten Zeit; nur flüchtig.
Slow Data bedeutet, mit Daten das Offensichtliche zu dekonstruieren und Alternativen aufzubauen.
Ethische Daten
Eine Wissenschaft gilt als nützlich, wenn ihre Ergebnisse dazu tendieren, die bestehenden Ungleichheiten in der Verteilung des Reichtums zu betonen oder wenn sie ganz direkt dazu dienen, menschliches Leben zu zerstören.
Godfrey Harold Hardy
Zwei Anwendungen dominieren die Big Data Diskussion, die das gerade Gegenteil von moralisch darstellen: Werbe-Targeting und Massenüberwachung. Wie Bruce Sterling betont, sind beide im Wesentlichen nur zwei Aspekte der selben Sache, die er “Surveillance Marketing” nennt. Es macht mich traurig, dass die prominentesten Anwendungen unserer Arbeit diese beiden sein sollen: Menschen Dinge zu verkaufen, die sie nicht haben wollen, und Menschen klein zu halten.
Ich bin allerdings zuversichtlich, dass der wohltätigen Nutzen von Big Data bald so lohnend erscheinen wird, dass wir aus unserem Albtraum des Military Marketing erwachen können. Mit Open Data errichten wir einen öffentlichen Datenraum. Sämtliche der äußerst nützlichen Big Data Werkzeuge sind ohnehin in der Public Domain: Hadoop, Mesos, R, Python, Gephy, u.s.w.
Ethische Daten sind Daten, die einen Unterschied machen, für die Gesellschaft. Ethische Daten sind relevant für das Leben der Menschen: Um den Verkehr zu steuern, die Landwirtschaft nachhaltiger zu machen, uns mit Energie zu versorgen, Städte zu planen und Staaten zu verwalten. Diese Daten spielen eine zentrale Rolle, das Zusammenleben von bald zehn Milliarden Menschen auf der Weld zu ermöglichen.
Slow Data sind Daten, die im Leben der Menschen etwas bedeuten.
Politische Daten
Es ist niemals der Zeit eines erstklassigen Mannes wert, eine Mehrheitsmeinung zu vertreten. Per Definition gibt es genug andere, die das schon tun.
Godfrey Harold Hardy
“Code is Law”; mit diesem Wortspiel betitelt Lawrence Lessig seinen berühmten Bestseller über die Zukunft der Demokratie. Vom Anbeginn der Internet Revolution wurde diskutiert, ob die neuen Medien- und Kommunikationsformen zu einer weiteren Revolution führen würden: Der politischen. Viele der Medien und Plattformen, die im letzten Jahrzehnt aufgestiegen sind, zeigen Eigenschaften gemeinschaftlicher oder gar gesellschaftlicher Systeme – und werden danach mit gutem Grund als “Social Media” bezeichnet. Es darf also nicht überraschen, dass wir die Entwicklung von Kommunikationsplattformen erleben, die auch eigentlich dazu gedacht sind, neue Formen der Partizipation zu unterstützen und gleichzeitig damit zu experimentieren. Proxy-Voting oder Liquid Democracy wären kaum vorstellbar, ohne die Infrastruktur des Web. Da diese neuen Formate um Politik darzustellen, zu debattieren und abzustimmen erst seit ganz kurzem auftreten, ist damit zu rechnen, dass weitere Varianten auftauchen werden, neue Konzepte, die das Internet-Paradigma auf gesellschaftliche Willensbildung übertragen. Nichtsdestotrotz, werden diese neuen Formen zu wählen auch funkionieren? Bilden sie tatsächlich den Volonté Generale in ihren Entscheidungen ab? Und wenn, werden sie über einen längeren Zeitraum nachhaltig, stabil und stetig weiterlaufen? Und wie können wir solche Systeme bewerten, eines mit dem anderen vergleichen? Ich arbeite augenblicklich in einem wissenschaftlichen Forschungsprojekt wie mit diesen Fragen umgegangen werden kann. Auch wenn ich heute noch keine Ergebnisse vorstellen kann, sehe ich dennoch schon jetzt, dass der Einsatz von Daten zur quantitativen Simulation ein guter Ansatz ist, die komplexe Dynamik zukünftiger, datengetriebener politischer Entscheidungssysteme anzunähern.
Politik bedeutet nach Aristoteles, den Freiraum zu haben, Entscheidungen ausschließlich auf Grund von Moral und Überzeugung treffen zu können, und sich nicht durch Nöte und Notwenigkeiten treiben zu lassen, welche er “die Ökonomie” nennt. Mit Gesetzen zu arbeiten ist in diesem Sinne vergleichbar zu meinem Beispiel über das Text-Mining oben. Sobald Gesetze kodifiziert sind, können sie quasi syntaktisch ausgeführt werden, in der Tat ziemlich ähnlich zu einem Computerprogramm. Was aber gerecht ist, was also in die Gesetze hineingelegt werden soll, ist ganz und gar nicht syntaktisch. Im Idealfall ist dieser Schritt ausschließlich der Politik vorbehalten. Ich glaube nicht, dass algorithmische Gesetzgebung wünschenswert ist, ich bezweifle aber auch, dass sie überhaupt möglich wäre.
Slow Data bedeutet, in aller Ruhe mit Daten neue Formen der politischen Partizipation zu testen.
Machinelles Denken
Schachprobleme sind die Choral-Klänge der Mathematik.
Godfrey Harold Hardy
“Können Maschinen denken?” Das ist die zentrale Frage der AI, der Forschung nach der künstlichen Intelligenz. Schon die Weise, wie wir darüber nachdenken, diese Frage zu beantworten führt uns augenblicklich aus der Informatik heraus: Was heißt es, zu denken? Was ist Bewusstsein? Seit den 1980ern gab es einen faszinierenden Austausch von Argumenten über die Möglichkeit von künstlicher Intelligenz, der im Streit um das Chinesische Zimmer zwischen John Searle und den Churchlands gipfelte. Searle und auf noch abstraktere Weise David Chalmers hatten gute Grüde vorgebracht, warum eine Simulation von Bewusstsein, selbst wenn diese den Turing-Test bestünde, doch nicht wirklich sich selbst bewusst werden würde. Ihre Gegenspieler, am bekanntesten Douglas Hofstadter, wiesen dagegen den Neo-Kantianismus von Chalmers als Metaphysik zurück.
Google hatte vor kurzem ein interessantes Paper über künstliche visuelle Intelligenz veröffenlticht. Dort waren mathematische Modelle mit zufällig aus Social Media Netzwerken ausgewählten Bildern trainiert worden. Und – Überraschung! – der Alorithmus kam mit dem Konzept “Was ist eine Katze?” um die Ecke. Der entscheidende Punkt ist, dass niemand dem Algorithmus gesagt hatte, nach katzenartigen Mustern zu suchen. Werden wir hier also Zeugen der Geburts von künstlicher Intelligenz? Auf der einen Seite leistet der Algorithmus genau, was Hofstadter vorhergesagt hatte. Er ist passt sich Umwelteinflüssen an und übersetzt Sinneswahrnehmung in etwas, dass wir als Bedeutung bezeichnen könnten. Auf der anderen Seite war der Trainingsdatensatz alles andere als zufällig. Die Bilder waren genau das, was Leute abgebildet hatten. Es war ein kollektiv kuratierter Satz mit ziemlich geringer Streuung. Die Muster, die der Algorithmus gefunden hatte, waren in der Tat vom “klassischen” Bewustsein aus den Köpfen ganz realer Leute in die Daten eingepflanzt worden.
Slow Data sind essentiell, um unsere Algorithmen intelligent zu machen.
Die Schönheit wissenschaftlicher Daten
Schönheit ist die erste Prüfung: Es gibt keinen dauerhaften Platz in der Welt für hässliche Mathematik.
Godfrey Harold Hardy
Nun kehren wir wieder zu Hardys Zitat vom Anfang zurück. Als ich Mathematik studierte, verwunderte mich der eigentümliche Ästhetizismus, den viele Mathematiker ihren Gedankengängen aufzwängten. Die Zeiten haben sich seit damals gewandelt. Heute haben wir viele Sätze bewiesen, die lange als schwere Probleme galten. Computergestützte Beweise haben eine feste Rolle in der mathematischen Epistemologie. Beweise, die tausende von Seiten füllen, sind keine Seltenheit mehr.
Naturwissenschaft und Physik im speziellen, wird durch akkurate Daten getrieben. Kepler konnte das einfache heliozentrische Modell widerlegen, weil Tycho Brahe die Bewegung der Planeten mit solcher Genauigkeit gemessen hatte, dass die Vorstellung von Kreisbahnen sich nicht länger aufrecht erhalten lies. Edwin Hubble entdeckte die Stuktur unseres expandierenden Universums, da Milton Humason und andere Astronomen am Mt. Wilson Observatorium spektroskopische Aufnahmen von tausenden von Galaxien angefertigt hatten, genau genug, um die Hubble-Konstante aus der Rotverschiebung der auffälligsten Fraunhofer-Linien abzuleiten. Einsteins Spezielle Relativitätstheorie basiert auf den Daten von Michelson und Morley, die gezeigt hatten, dass Licht sich stets mit konstanter Geschwindigkeit ausbreitet, egal in welchem Winkel zur Erdbahn um die Sonne man sie misst. Diese kompromisslos genauen Daten, in mühevollem Kampf gesammelt, ohne dass irgendein Erfolg garantiert gewesen wäre – diese Daten stehen wirklich hinter den großen wissenschaftichen Durchbrüchen.
Schließlich, während also die Mathematik langsam sich in Syntax verwandelt, entfaltet die Physik in ihrem Herzen die seltensten und überaus schönen Blüten, die man sich vorstellen kann. In der Schnittmenge von Kosmologie, die sich mit den größten überhaupt vorstellbaren Objekten beschäftigt, und der Quantenphysik, auf der allerkleinsten Skala, liegt die fremdartige Welt der Schwarzen Löcher, der Stringtheorie und der Quantengravitation. Der Maßstab dieser Phänomene, die Textur der Raum-Zeit selbst, definiert durch das Planck’sche Wirkungsquantum in Verbindung mit der Gravitationskonstante und der Lichtgeschwindigkeit, ist so unvorstellbar klein – etwa vierzig Größenklassen unterhalb der Größe eines Elektrons – dass wir kaum erwarten dürfen, irgendwelche Daten dazu in naher Zukunft tatsächlich zu messen. Wir können uns also nur auf unsere Logik verlassen und unseren Sinn für mathematische Schönheit und unseren kreativen Geist.
Slow Data
Slow Data – Für mich wird der Raum von Beautiful Data durch diese Aspekte aufgespannt. Ich bin zuversichtlich, dass wir keine neue Fassung unseres Manifests brauchen. Ich hoffe jedoch, dass wir viele Beispiele sehen werden, von wertvollen Daten, von Daten, die Menschen helfen, die ungesehene Erlebnisse erzeugen und die uns die Türen zu neuen Welten unseres Wissens und unserer Vorstellung öffnen.
Anhang: Slow Media
Die Slow Media Bewegung wurde durch das Slow Media Manifest gestartet, das Sabria David, Benedikt Köhler und ich am Neujahrstag 2010 geschrieben haben. Unmittelbar nach der Veröffentlichung des Manifests wurde es auf Russisch, Französisch und etwa zwanzig andere Sprachen übersetzt.
Auf unserem Slow Media Blog finden sich weitere Texte zur Slowness:
Auf Deutsch: slow-media.net
Auf Englisch: en.slow-media.net
außerdem: “Slow und Open Source als Alternative zum Plattformkapitalismus”